At WAIR-Research, our primary objective is to develop foundation models for the time series domain, which help us perfect our sales forecasting capabilities for our AI-replenisher.
Specifically, we are developing deep-learning models that have a general understanding of the broader time series domain as a whole, enabling them to carry out a variety of tasks (amongst them retail forecasting), without needing retraining. This approach stands out from the “traditional” understanding of machine learning for time series data, which requires re-tuning models to learn a specific dataset or task. Besides being less flexible, this traditional method is also slow and scales terribly with the number of series considered. At WAIR, we make predictions for millions of product sales patterns (time series) every day, demanding a more innovative approach that works out of the box.

T-shirt 1104292
To make it a bit more concrete, consider the sales of a given product (e.g. T-shirt 1104292) in a given year, that was launched on the 1st of April. Traditionally, time series analysis begins by splitting a single series into training, validation and test sets along the historical time axis. You could take the sales from April-June as train data, validate on July’s data and then test on August and onwards.
Then, traditional methods like ARIMA are employed, requiring a (potentially manual) search for optimal configuration (hyperparameters) to achieve good performance on the validation set. This approach then assumes that the forecast performance on validation in July will generalise in production to future test sets for that specific product, like October, November, etc.. The whole approach also fails to consider other products, so is limited to the information in the history of our specific T-shirt and it assumes a long history for this product to be available.
As such, this method faces significant challenges with cold-start (new products with little historic data) and non-stationary (sudden changes in sales patterns, for example seasonality). Additionally, the entire process must be repeated whenever new series are presented, making it time-consuming and practically inefficient.
Traditional train-test-validation split for forecasting, creates large distance between train and test sets in production
Instead, we decided to create a single model capable of handling different types of series and predicting multiple series efficiently in a single prompt to the model. To do so, we drew on the concepts of:
- In-context learning:
being able to learn extremely quickly by looking at only a few relevant examples of related sales patterns, at test time.
- Representation learning:
to model the process that generated the time-series, rather than its observed values alone – recognizing the fact that time series are inherently stochastic.
We’ve recently published our first scientific paper on the subject: LaT-PFN: A Joint Embedding Predictive Architecture for In-context Time-series Forecasting, which introduces our new foundational model for time series data:
LatentTimePFN-1.0 (LaT-PFN)
LaT-PFN is able to forecast on any time granularity (daily, monthly, etc.) and prediction horizon (2-weeks, 8-weeks, etc.), without needing extensive retraining. Thus, saving time and resources.
In the next sections, we will go further into the aforementioned frameworks, elaborate on our model design and then demonstrate the model’s performance.
1. Exploiting a User-provided Context for Quick Adaptation
In-context learning is a machine learning approach where a model makes predictions based on patterns it observes not only with the regular input data, but also with a provided context of related series, without needing additional training time. Instead of being re-trained with new data for each specific task, the model uses the provided context to understand and respond to new inputs.
Conceptualization of in-context time series forecasting
Here’s how it works:
- Observation: The model receives a bunch of example sales series, each with data points (the context). These examples are assumed to be related time series to the target series.
- Pattern Recognition: It identifies patterns, trends, and relationships within this context. All of this happens at test time.
- Prediction: Using the recognized patterns, the model makes predictions for new, unseen series / data points.
Previous approaches use only historical data of the same product’s sales pattern. Instead, we define a context as a set of examples of other product’s sales patterns, which contain the additional information the model needs to predict the target sales pattern. Using examples provided by the user, the model can adapt to new products quickly and efficiently, without requiring the time-consuming retraining process.
As an example, consider a scenario we encounter frequently at WAIR. Imagine you are forecasting a particular product’s sales for the month of June, starting on the 1st of the month. The product hasn’t been on the market long, and you have only a few weeks of historical sales data. Traditional methods would not be able to use this data, yet with LaTPFN we can, since we approach it using an exemplary context.
One could approach this as follows; First, we mark the product’s (short) history as the unseen data. So far it is business as usual. Next, you gather the sales data of related products – in the same category – from exactly one year ago, to form the context. Since these are last year’s products, you already know their sales realisation for June of the previous year. Both the unseen data points and the context from last year are mapped to a normalised time axis, centred around prediction day June 1st – ignoring the year. This combined data is then fed into LaT-PFN to obtain a forecast.
Example of taking historical data ( top) and
mapping them to one context centred around relative forecast date (bottom)
This approach leverages the assumptions that products may share similarities and follow seasonal patterns. However, LaT-PFN is flexible and also accepts the context to be formed by other methods – not just using a year-offset with related products.
In fact, any context that can inform the prediction is utilised by the model, if the model thinks it looks informative, allowing for a dynamic interaction to determine the best context. This is similar to how one designs an optimal prompt for a large language model (LLM) like chatGPT.
What are Embeddings and Why Are They Convenient?
Conceptualization of Embedding creation
“Embedding” or “Representation Learning” is a technical method to represent any data format in a more compact and practical way. An embedder-model uses Representation Learning to create an “embedding” of – for example – a picture.
You can think of these embeddings as summaries. The technique is commonly used in machine learning to convert complex, high-dimensional data – like pictures, text, sound, time series – into a simpler form, while preserving the essential relationships and structures within the data.
Here’s a breakdown of the concept:
- Dimensionality Reduction: Imagine if you had to analyse each pixel of a picture as a column in a spreadsheet. High-dimensional data, like words in a text or features of an image or a time series, can be hard to work with directly. Embeddings reduce the size of the problem while capturing the most important information.
Visualisation of LaT-PFN time series embeddings (bottom) against original time series (top)
Vector Representation: Each data point is represented as a vector (a list of numbers) that summarises that data. In our work, we have embeddings per time step (day) of the (sales) series which can also be aggregated to a series-wide summary vector, capturing the pattern of the whole product.
Semantic Relationships: Embeddings are designed so that semantically similar data points are close to each other in the vector space. This way we can reason about relationships between series using the proximity of their embeddings.
Learned from Data: Embeddings are typically learned from large datasets using machine learning algorithms. The process involves training a model on the data so that it can map inputs to the embedding space in a meaningful way.

Representations of time series embeddings from LaT-PFN demonstrate the model learned to group series by concept
Another example: for pictures of hand-written digits, embeddings which are close together belong to similar looking numbers
So, why are we using embeddings?
- Embeddings allow us to build multiple downstream applications on the same model. For example, we can simply plug-and-play a time series classification task or similarity search task on top of the model that was trained for forecasting (see section 5).
- Additionally, these specific embeddings enhance the performance of forecasting. Time series are inherently stochastic processes. The observed values can be viewed as noisy samples from the underlying generative process. Therefore, it pays off to focus on this process and predict its potential changes over time. Simpler said, to not get distracted by the details.
Encoding Expert Knowledge into Synthetic Training Data.
We set out to handle multi-domain data (retail, financial etc.) dynamically in one model. As such, we need a domain-agnostic dataset with in-context sets. We approach this by training on synthetic data, where we can encode technical expert knowledge about general time series properties into our training data, and granting us a high level of control.
One can wonder how the model will then figure out which domain it is in. The domain insertion (like retail, banking, etc) occurs later at inference (production) time, through the context. Essentially, The model is trained to learn to complete generic time series based on their shapes (trend, seasonality, etc.) and the user-provided context is then allowing the model to then recognize the type of series and the specific domain – in which subdomain of the extend of simulation it is in.
Full Model
Note: this section is a bit more technical, skip to section 5 for casual reading
To bring it all together, our model design is pictured below.
The model features three loss components, which it learns to minimise during training:
- JEPA Latent Loss: This compares the embeddings of the embedding prediction with the embedding target. It is using the history and input-context to make this prediction. This loss gets lower when the model gets better at predicting the next embedding, which helps to create strong, robust embeddings that contain all information for downstream applications – like forecasting.
- PFN Forecast Loss: This compares the decoded embeddings with the actual forecast target. It gets lower whenever the real forecast gets more accurate and optimises the model’s final forecasting capabilities.
- System Identification Loss: This compares the simulation parameters with their reconstructions. This loss regularises the model and adjusts its focus to the generative process, ensuring it accurately captures the underlying dynamics of the data.
Practical Value
Our approach has several benefits:
Handling Cold-Start Problems: Many time series datasets suffer from cold-start problems, where there is little historical data available for making predictions. Our approach helps mitigate this issue by using similar examples from the context dataset to inform the model, thus improving its ability to make accurate predictions even with limited historical data.
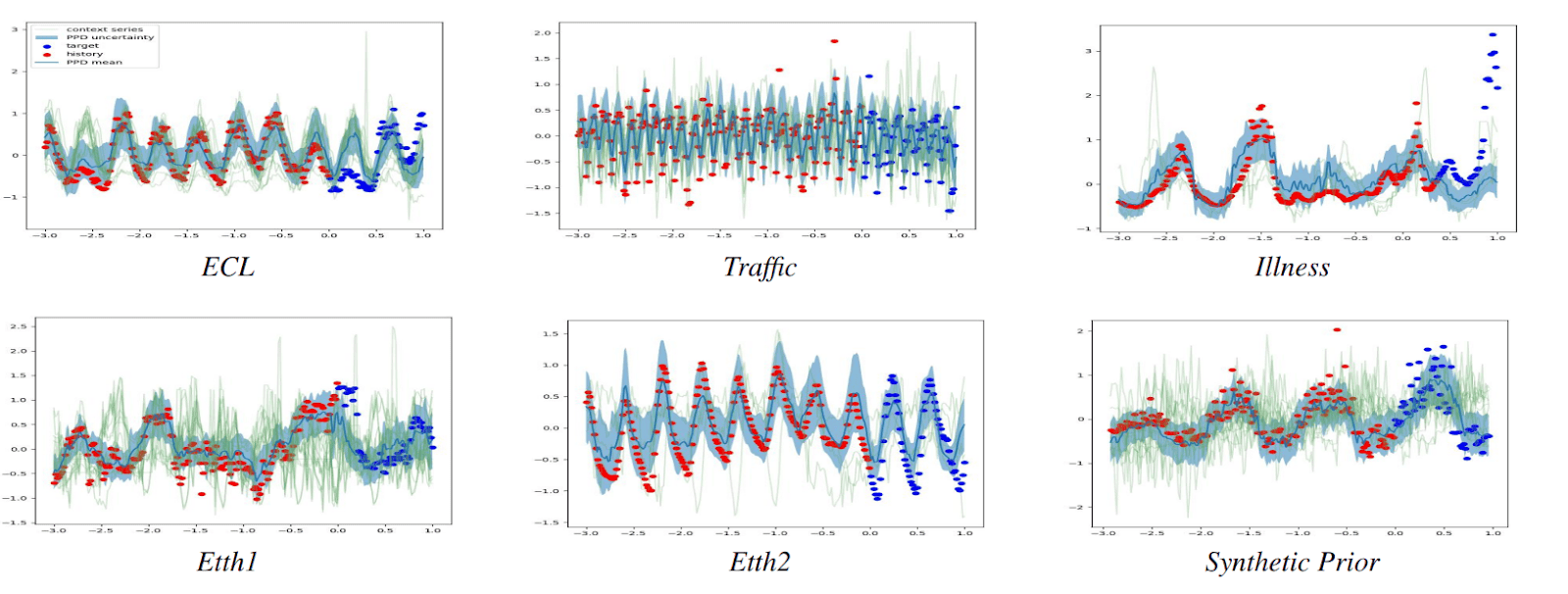
LaT-PFN out-performs many state-of-the-art baselines
Adaptability to Non-Stationary Data: Time series data often exhibit non-stationary behaviour, where statistical properties like seasonality change over time. By predicting the next embedding we allow the model to adapt to these changes.
No Need for Extensive Retraining: Traditional time series models often require retraining for each new dataset, which is resource-intensive. Our approach enables the model to make predictions on new, unseen data without the need for retraining. This saves significant time and computational resources.
LaT-PFN shows strong forecasting performance on a wide range of datasets, without ever retraining. Red dots are the historic sales, blue dots the forecast target, blue line is the forecast, green lines are the context and blue fill is the uncertainty.
Improved Generalisation: By understanding the context of similar time series and training on embeddings, the model can better capture the underlying patterns and stochastic processes that drive the data. This enhances the model’s ability to generalise from these examples, improving its performance on new and diverse datasets.
Efficiency and Scalability: Since zero-shot forecasting does not require extensive retraining, it is more efficient and scalable. It can handle a large number of time series without the need for individual model adjustments, making it suitable for applications where multiple time series need to be forecasted simultaneously.
Similarity Search: LatPFNs embedding space allows to find similar series using simple similarity search, as well as finding similarity in patches. This can power applications that help analysis in big datasets.

Finding similar patches of series (blue) using query patches (red)
Quickly build new applications: LatPFNs flexible embedding space also makes it easy to quickly build other applications on top of the embeddings of series. This is showcased below by a new classification task without retraining, reaching a high score, even when it was not trained on this data, in contrast with baseline TS2Vec.
LaT-PFN outperforms TS2Vec on classification even though it was not trained on this dataset
Conclusion
In conclusion, WAIR Research enables cutting-edge (sales) forecasting solutions that effectively address the challenges of traditional time series analysis. LaT-PFN is only the tip of the iceberg! Our innovative approaches ensure accurate, efficient, and adaptable forecasting across various domains. If you are interested in learning more about our offerings and how they can benefit your business, we invite you to schedule a meeting with us. We look forward to discussing how our solutions can meet your specific needs and drive your success.
Authors: Stijn Verdenius & Andrea Zerio